


Value Vector: Are LLMs Mirrors or Minds?
Value Vector: Are LLMs Mirrors or Minds?
Rethinking the Turing Test in the Age of the AI Boom.

Today, we’re going to take a moment to comment on Large Language Models (LLMs) — the technology1 driving the AI boom. But beyond the hype, what are these models really? Are they independent minds, or simply mirrors reflecting our own intelligence?
Then later this week, we’ll dive deeper into the business fundamentals of the hardware that powers these technologies in our first Weekend Workshop (turned Daily Brief).

If you’re eager for a more in-depth commentary, you can find the full essay [here]. Below is a summarized version I wrote with one of my AssIstants.
Are LLMs Mirrors or Minds?
N.H. Pavao
August 31, 2024
Abstract
In this essay, I introduce the concept of Turing’s Mirror, a new dimension with which to evaluate large language models (LLMs) that augments the traditional Turing Test.
The Turing Test is one way to evaluate machine intelligence and model performance2. The test assesses whether a machine can engage in a conversation indistinguishably from a human. However, this implicitly assumes that LLMs are agents with measurable intelligence that can be compared to some threshold.
Turing’s Mirror, by contrast, proposes that LLMs are more like mirrors—reflecting the cognitive abilities and verbal sophistication of the person interacting with them.
This perspective implies that LLMs might pass the Turing Test when queried by experts, but fail with simpler queries from non-experts, revealing their role as pattern recognizers rather than genuine thinkers. This shift in understanding could reshape how we develop, deploy, and evaluate LLMs.
The AI Boom and the Rise of LLMs
Since the launch of ChatGPT in late 2022, the capabilities of LLMs have improved dramatically. What once felt like talking to a parroting chatbot—clunky and repetitive—now feels like engaging with a nuanced and insightful conversationalist. This leap in performance isn’t magical; it’s the result of scaling up compute power and data.
But it raises a deeper question: Are these models truly intelligent, or are they just better at reflecting our own intelligence?
Rethinking the Turing Test: Turing’s Mirror
The Turing Test has been the benchmark for machine intelligence since the 1950’s: if you cannot distinguish a machine from a human in conversation, the machine is considered intelligent (at least in the human sense).
Traditionally the Turing Test has two outcomes:
The machine fails (clearly distinguishable from a human)
The machine passes (indistinguishable from a human)
Here’s the general idea: humans have a standard of verbal fluency - once a machine surpasses that threshold (as evaluated by the test administrator), it has passed the test:
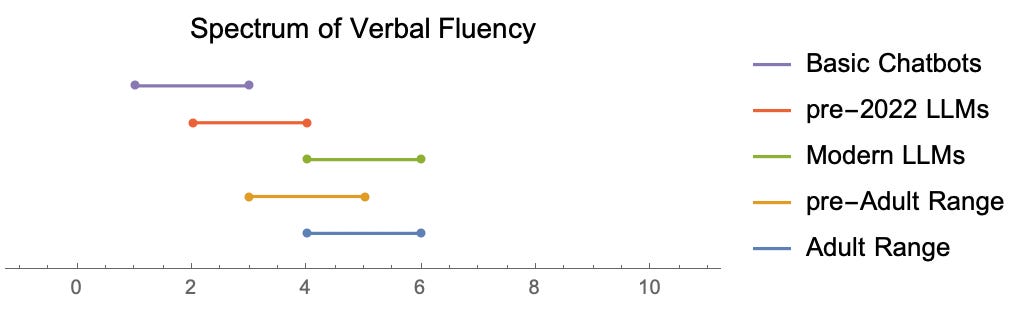
Above, basic chatbots and pre-2022 LLMs (at least the publicly available ones) lacked the verbal fluency to pass the Turing Test. In contrast, most experts today would say that the industry scale models today have successfully surpassed this threshold.
But what if this test doesn’t actually measure the machine’s intelligence?
What if the LLM is more like a mirror, reflecting the cognitive abilities of the person asking the questions? Something like this:

Above, we have a spectrum of test administrators from novice (left) to expert (right) — and they sample different verbal fluencies (in green) from the same model (range given in orange).
So in the essay I propose an alternative outcome: Turing’s Mirror, suggests that when we interact with LLMs, we’re not assessing an independent mind but are actually seeing a reflection of our own knowledge and sophistication. This means that an expert might receive complex, insightful responses because the LLM mirrors their advanced understanding, while a non-expert might get more simplistic answers.
So my claim is that the Turing Test as stated is not MECE. A full set of outcomes would look something more like this: a machine taking the test can
fail because it is limited
fail because it is capable, but test administration is limited, and
pass because it is capable, reflecting the capability of test administration.
The combination of outcomes 2 and 3 capture the essence of Turing’s Mirror.
The Implications of Turing’s Mirror
This explains why perceptions of LLMs are so widely varied. Technical experts often view these models as revolutionary because they see their own depth of understanding reflected back at them. Meanwhile, non-experts may see LLMs as little more than advanced chatbots, capable of generating coherent text but lacking true reasoning or creativity.
This difference in perception isn’t about the LLM itself—it’s about what the LLM reflects. The model’s intelligence is largely a mirror of the user’s cognitive abilities. For those who push the model with sophisticated queries, it seems almost human-like. For others, it remains limited by pattern recognition.
Maximizing LLM Capabilities
Understanding LLMs as mirrors changes how we can best use them in industry and business settings:
Invest in Expertise: The more knowledge and clarity you bring, the better the LLM’s responses will be.
Iterative Querying: Refine your questions to uncover deeper insights.
Cross-Disciplinary Synthesis: Encourage exploration across fields to generate innovative responses.
Clarity in Communication: Precision in your queries results in better, more valuable outputs.
Conclusion: Are We Asking the Right Questions?
As we stand on the brink of a new era in language modeling, Turing’s Mirror challenges us to reconsider what we’re truly evaluating. Are the perceived limitations of LLMs inherent, or are they simply reflections of our own limits in querying? The future of LLMs might not lie in bigger models but in better interactions.
Indeed, we maybe already be interacting with machines far beyond our capabilities (shown below), but which are constrained by our limited capacity to ask the right questions (thanks, Douglas Adams).

In the end, Turing’s Mirror prompts us to rethink not just the nature of LLMs, but the nature of our own intelligence. The most profound insights may not come from the LLM itself, but from how well it reflects and enhances our understanding.
There are of course other more analytical ways to test model performance, including measuring their loss function when tested against validation data.